New paper in Neurocomputing: Deciphering the transformation of sounds into...
2 October 2026
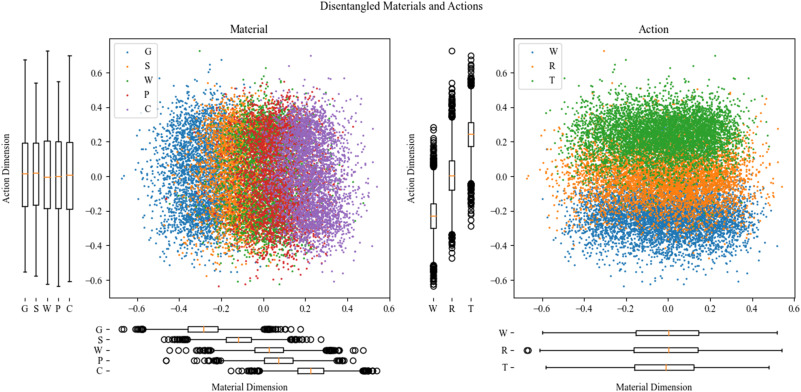
In neuroscientific applications of deep neural networks (DNNs), interpretability of latent representations is crucial. Otherwise,...
