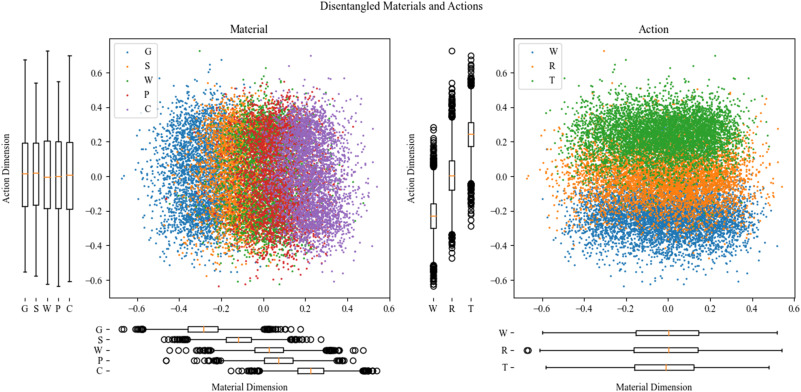
New Article in IEEE Access: Audio-Language Datasets of Scenes and Events: A Survey
7 February 2025
This work - published in IEEE Access (Open Access) - offers a comprehensive analysis of many audio-language datasets used to train audio-language models, examining dataset origins, audio-linguistic characteristics, and use...